I’m biased against AI. It’s not out of ignorance. I studied AI in college. I worked in speech recognition research during college and after college. I have a patent in speech recognition using hidden Markov models. I’ve designed a VLSI chip to do parallel processing for neural networks. This isn’t to brag (ok, maybe a little); it’s to say my opinions aren’t based on ignorance, or at least not complete ignorance.
My experience in AI taught me that I never wanted to work in AI again.
People have a weird psychology about AI. One of my favorite stories is about this AT&T study where they had a speech recognition system that could understand digits at something like 99.6% accuracy, and it turns out that that’s more accurate than a phone’s buttons. When you push a button on a phone (at least on an old phone that used DTMF - dual tone multi frequency), the phone would translate the digit on the button into two frequencies that it would play at the same time. That sound was then encoded and transmitted digitally (or sent analog over really old lines) to some receiver system that would then decode and interpret the signal back as a digit. It turns out that this isn’t perfect. There’s noise in the system, and sometimes the system would “hear” the wrong digit. But when people pushed a button and got a wrong number, they assumed it was their fault. You know your fingers aren’t 100% accurate. People are clumsy. So they’re willing to take the blame when something goes wrong. They assume the button itself is 100% accurate, and it must have been them. I’ve done this myself, of course, and usually assumed it was my fault. And most of the time it probably ways. I hit the wrong button, or hit two buttons at the same time, or didn’t press it long enough. Whatever. But I’ve also hit the redial button to replay the exact same digits, and had it work one time and fail another. But the point is, psychologically, people tolerate less than 100% DTMF and it’s fine. But voice - that’s a whole different thing. Again, AT&T had higher accuracy in their digit recognition system, but people always thought their voice was perfect, and if the system didn’t recognize it, it must be the system that was wrong. Now, this is quite stupid. Objectively, people do all sorts of bad things with their voice. Mumble, speak softly, even literally say the wrong digits, but they don’t believe any of those things are justification for a system getting them wrong. Even between humans, if I say something and you hear it wrong, it must have been you, because my voice is infallible.
When we were training speech recognition systems, we’d start with training data recorded from real people speaking. But the problem with training data is that it’s not perfect. Before you train something on a sample of words, you need to know what those words were. So you’d have them transcribed by a human. I’d sometimes listen to the samples and reason that whoever transcribed it actually got it wrong, that the sample was saying a slightly different word. And this makes sense because people transcribing are under time pressure, maybe even paid per word, not per hour, so they rush through and make their best guess. And I, as a researcher, might be willing to listen to it 5 times to make sure I really knew what they said. But also sometimes I’d listen to a sample 15 times and still not have a clue what the person was saying. It was, by definition, unintelligible. People say things that aren’t even words, yet fully expect another person, and speech recognition systems, to understand them anyway. So it’s really hard to work in an industry against that kind of pressure. Weirdly illogical.
But back to GenAI, sure it seems to be different. ChatGPT is amazing. It’s not perfect, but it exceeds expectations and so everyone’s happy. And maybe it will fundamentally be different this time around.
Or maybe, it’s just because it’s hovering around 80% accuracy right now, and everyone knows that they need to check the results. They don’t tie GenAI into important systems without having humans in the loop. And maybe it’s only used in domains where 80% accuracy is good enough. But when it gets to 90% will that change? Will people start accepting a marketing landing page that is 90% accurate? Maybe for some outreach campaigns. I mean, let’s face it, spammers are going to use it at that point for sure without bothering to read the results. Heck, they probably already are. But for legit marketers? No, they’ll have too much integrity for that, of course. But at 95% does it change? 99%? What about 99.6%?
Somewhere around 99% accuracy, people will stop putting humans in the loop, stop using AI to augment your work and start using it to do the work. Stop being a co-pilot, and become the pilot. (Although that’s quite unfair to actual co-pilots that do, in fact, fly the plane too, but it’s the metaphor the industry seems to be going with at the moment.) And it’ll be justified because the accuracy will be higher than the majority of your employees anyway. I mean, how many employers can really claim that all of their employees are above 99% accurate in everything they do? Put that way, it’s kind of silly. So it’ll be a net win, right!?
But whether it hits the trough of disillusionment, or the uncanny valley, it’s going to freak people out. Suddenly, there’s going to be a backlash. Big companies will be called out for some tiny mistake in their ad copy because someone proves that it was generated by AI, and that it was wrong. On the other hand, other people will do research and prove that the error rate of AI is actually less than humans, so shouldn’t we all celebrate? But it won’t matter. A Tesla car crashed, so let’s block all self-driving cars, even if the world would be better off if every car on the road was self-driving, because let’s face it, humans suck at driving. But if I’m going to die in a car wreck, I want it to be because of my mistake, dammit! How dare you crash far less often, but in different ways that I would have never crashed in. I’m infallible!
So will GenAI survive this backlash? Oh probably. Heck, speech recognition systems didn’t go away. But it took 20 years to go from a demo that sounded an awful lot like talking to Siri or Alexa, to actually having Siri and Alexa in mainstream consumer devices (and actually stay there rather than be rejected). Will it be another 20 years for GenAI to get past its own chasm? Who knows. Maybe it’ll be faster. This wave of AI does feel fundamentally different than 30 years ago. But I’d be willing to bet that a ton of the recent GenAI companies are going to flail and fail and at some point it’s going to be miserable and frustrating working in GenAI. And when it does mature, it might not be from any startup at all, but something the likes of Apple and Google bring to the market.
Back in the Fall of 2017, I had an internal conversation with the product team at GitLab on Product Discovery. Since we’re transparent by default, the session was recorded and posted to YouTube. The original video and a loose transcription is below. Enjoy!
Mark: Well, this was an item that rolled over from last week, but it came up a couple of times and it’s actually been coming up a lot lately; the idea of Product Discovery, versus, whatever it is we call what we do today. I’ve been thinking about how to approach this. I was even tempted to organize a workshop or something where I can describe what it is that I mean by Product Discovery at least . I’ve also been tempted to do an experiment with a team or two to do a Product Discovery sprint, or more than one or whatever, and slowly introduce it. But what I’ll do today is just talk about it meta a little bit: what it is, why I think it’s important for us to understand what product discovery means, and why we should consider doing an experiment; and then see what you all think about it and whether we want to go forward or not.
So I did include a link to a bad blog post I wrote at some point. It’s not very long or detailed , but it’s the extent of my notes on the subject, unfortunately.
This is actually derived very much from work I did at Heroku, just to be upfront, and how we did Product Discovery there. And it’s a process that we, discovered so to speak, sort of accidentally. The reason I say that is because it also looks very similar to Lean Startup, but we didn’t know that until after I read the book later, months later. But to be fair, a lot of it was also probably inspired by, one of the founders of Heroku who had been mentoring me on stuff and he had gone through YC. So I don’t know, there’s probably some relationship between YC and Lean Startup and so it’s all related, but the point is, it sounds a lot like Lean Startup, but I didn’t actually read the book yet.
Actually originally it was derived from an interview. At Heroku, we did week long starter projects and I came up with this really compressed schedule because I wanted something for a candidate where the work was nearly guaranteed to succeed and I was just interviewing the candidate on what it was like to work with them. And so I came up with this really aggressive thing: let’s make a tiny, tiny little sliver of a feature that we can guarantee we will ship within a week. In fact, to make sure we guarantee we ship it, let’s guarantee we ship it in two days. And then we’ve got the rest of the week; in case we screw up radically, we can still fix it in the three days left. it turned out though that we actually shipped an amazing amount of stuff in a week. And it was awesome and it was an eye opening experience for me, which is one of the reasons I want to share it with you.
So we stumbled on it during this one starter project and then slowly it sort of calcified into this process that I’m going to describe. And it turned out that , anytime we ended up challenging the process, we basically said, no, this process works exactly as it is. But if there was a challenge, it was an interpretation of how we were supposed to do things, but it was just like the process actually really worked, which is also especially funny because we started with this whole thing because our old process wasn’t working and we threw out process entirely. And so all of this was generated from scratch from a couple of people who basically said, “scrum sucks; all this planning poker and all these other things are just a total waste of time, let’s throw out all process altogether and let’s just talk”. And then we ended up coming up with this very rigid process, which is just ironic if nothing else, but it really, really works because it was based on better principles . I’m not saying scrum wasn’t based on better principles, but it wasn’t working for us. Also to give a little more emphasis on this, I was literally working with a team of eight people and we were doing scrum and every sprint, we do a weekly sprint, every sprint, we try to squeeze out a few percentages improvements in our process, but the things were still just horribly bad. We spent a whole bunch of time like “okay, let’s iterate on making sure that we’ve got really good high fidelity mockups”, so the engineers have something better to work with than the low fidelity mock-ups. And then we’d still have problems where the engineers would implement something wrong, whatever. So then we got even higher fidelity mockups. Then we got like, “well, let’s annotate the mockups with the exact dimensions of things”, or “let’s talk about the things we care about”. Because back then we were using Photoshop too. And gradients that didn’t exactly translate from Photoshop to CSS. And so people would always interpret things a little bit differently and one of the struggles was the designer was like, “I want to just say , I don’t really care about this. I want it to look like this. Don’t follow my Photoshop mock-up exactly because it’s not CSS, but this one I do care about; this really has to be five pixels, don’t make it three or seven, it’s got to be five”.
And so we ended up literally mocking this up, like an engineering architecture diagram ,and we had this really, really rigid thing. So Product and Design would work really, really closely. And then we’d still throw it over the fence to Engineering. And so the best we got to was we would do that. We’d spend a week mocking up something, and then we’d give Engineering two weeks before they’d pick it up. And that was based on a recommendation from, Marty Cagan’s book. and then engineering would pick it up and then they’d work on it for a week and then they’d show out at the end of the week on demo day, and then we’d see it and then be like, “okay, well that looks pretty good”. And we’d come up with some immediate things, but then after we go to use it, we come up with more. So we’d come up with all the bug fixes over the next week. We’d feature assurance as Product. And then the following week Engineering would pick up all those bugs and then deliver it. So, net we’re talking about , I don’t know, five weeks of time, calendar time with, with a pretty large team.
When we ended up doing this product discovery process, we basically delivered that, that same kind of thing in one week with half the people. And so I roughly speaking, say that this was like a 10 X improvement, not in terms of lines of code, but in terms of wall clock time, of idea of a feature to delivery of the feature; one week time. Also, the quality was much better because we didn’t have these stupid misinterpretations between Engineering and Design. And worse is the feature assurance part. A lot of times you design a static mockup with the ideal lorem ipsum lines of text, and you say, “okay, let’s put three lines of text” and it turns out that in fact, people don’t use three lines of lorem ipsum. They use weird bullets and they use 20 lines in fact and they use all these other things and designing with real data is really, really hard. So a key thing about this is within 24 hours, we’re actually working with real data, we can see whether it really works or not, and we can iterate the next day or the next four hours in fact to make changes based on that. Also I banned lorem ipsum; we will never use lorem ipsum again. I always used at least realistic data, but still that wasn’t enough. You had to have actual real data.
So anyway, all sorts of things learned. I’m going to try and speed this up just a little bit; I know we’ve got an hour, but I don’t want to use up all of it. So anyway, the idea here… key things are: Product did not fully spec things out before passing off to the team. Things were just spec’d enough to know that we could deliver in a week, that it was viable to deliver in a week at least, and we had at least some belief that it was an important feature, and we had a hypothesis, that if we do X, then this will improve something. What we would then do is take that sort of nub of a topic and we’d do this Think Big session and the Think Big session would literally be a couple of hours long and we’d really open it up to brainstorming, but also… There’s some subtleties here that it’s really hard to express, but… One of the big things about Think Big and the brainstorming in general is not the actual brainstorming per se, but it’s about getting the whole team on the same page so that all the ideas are now shared instead of having three different people, all having different parts of the stuff in their heads and talking about it on an issue where they only talk about some small intersection, but not really actually being on the same page. And you do the Thing Big session and, invariably, we found just people were on the same page afterwards. Product and Engineering and Design and everybody knew, basically, the entire scope of what we could possibly be talking about here.
Also an important thing about the Think Big was: totally disregard, limitations, like whether something was feasible, whether you could do it on a week or not. Even though of course the ultimate goal is to deliver in a week. In the Think Big session, it was like: let’s radically rethink everything we could possibly rethink on this topic. I know that’s kind of broad and scary, but again, it’s only two hours, so, you know, but it helped you then open up ideas that you had never thought about before , like what if we didn’t just do this, but what if we threw that whole thing out and did something else instead. And sometimes you ended up being like, “Yeah, actually that sounds like a really good point. This idea that we thought was really worthwhile actually isn’t, let’s do something else.” It doesn’t happen very often, hopefully but you know it sometimes does. But more often, it’s just, it gives you a bigger perspective of what’s going on again, being on the same page.
Anyway, then a really crucial part was the Think Small. And this was again the accidental thing because I was just trying to make sure that the starter project worked, but we really said what can you ship in 24 hours. In practice we’ve hardly ever shipped in 24 hours, so it’s really more like 48 hours. Although at some points, we got really good and got it down to 24 hours. But the net idea is you’re starting on a Monday, let’s say by Wednesday, you’ve got the first iteration ready by Wednesday lunchtime, not Wednesday end of day. And you’ve got the first iteration and it’s going to be ugly and it’s going to be disappointing and it’s going to be whatever, but it’s going to functionally be there. And it may as well just go along with the story now. This first time we did this, we had the Heroku status site. It told us, told the customers whether Heroku was experienced an issue or not. And it was all manual entry done kind of stuff. We had completely revved that site. It’s now dead, so if you look at it, it’s not that site, but it lasted for a good several years.
Well in the top right hand corner was a little place where we wanted you… But actually, while I was there, it was a place to subscribe to stuff. But before that existed, there was no place to subscribe. The idea was… We said, “okay, if Heroku is down, it’s great that I can discover this there’s a problem and then go and check the status site, but why don’t you just tell me that the damn thing’s down or even better during the command line, tell me if things are out or whatever, but just tell me proactively that something’s down instead of warning me. Especially since you don’t necessarily discover things until your customers are complaining about stuff. And so this was back before any of this stuff was automated. So we said, let’s let people subscribe to notifications on the status site and that was it. To flesh out the story a little bit more, I went in as Product Management thinking a couple of things were key. I thought people are going to want to be able to subscribe by email, but they’re probably also really gonna want to get text messages because they’re not sitting there by the computer all the time and I want to be alerted in the middle of the night if my critically awesome important website is about to go to the VCs and Heroku is down. I need to know about it. So be able to text me, maybe even phoned me, I don’t know, but at least somehow communicate on my device.
And then I thought as a user, you already have my login. So don’t make me create a new account. Don’t make me log in again. Or maybe make you log in, but then get my email address from my login. And I thought that was a critical piece. Those are the only things that I really thought about. Beyond that. I said, okay, I don’t know what else there is.
The awesome thing is during the Think Small session, one of the developers was like, “Well making you log in first and everything else, that’s actually really hard. What if we just make you type in your email address again?” And I was like, “Well, that makes no sense. You already know my email.” But if I make you log in, you’re gonna have to type in your email address anyway, to log in. This way we’re at least not asking you to type in a passwor; let’s just type in your email address. And then I was like, “Well, how do you unsubscribe? How do I go to my settings to unsubscribe.” He’s like, “Well, you get the email. Click on the link to unsubscribe. You don’t need account management system. You just need an email and an unsubscribe mechanism.” And that simplification which was awesome, came from a developer, scoped it down. Which, I will honestly say in the entire history of Heroku, we never tied the login systems together. This thing that I, as product management thought was critical, was not. And in fact, made it awesome to not do it. Because of course, there’s this obvious downside of: if Heroku goes down, how the hell do you log in to go and do anything on the status site? That’s kinda dumb, like decoupling these things makes a lot of sense. Just a good little lesson learned there: this is why this stuff’s important and why it’s important not just to have Product involved, because Product can be done sometimes and think that something’s important when it’s not.
So anyway, so Think Big, Think Small, you get it down to what can you ship for the next 24 hours. And then you actually go and work on it. And, and again, the first version we had showed it to a bunch of people including one of the founders of Heroku. And he’s kind of like “Meh, whatever. Fine.” Not the experience we were looking for. We were hoping he would be like, “Oh yeah, this is cool. I can see that it’s ugly, but I can see the potential.” But he’s like, “no, whatever,” just didn’t care. But then we iterated on it and at some point… We started off with roughly speaking rail scaffolding. I don’t think it was actually real scaffolding; I’m sure it used our own CSS, but it was still roughly speaking scaffolding. And then we said, “okay, it’s gotta be integrated a little bit better.” And so we ended up putting it in the toolbar, or not in the toolbar, there was no toolbar, but we put it in, the top right hand corner. And so there’s a little subscribe link and we made it all a single form, popup, whatever. So a bunch of GUI optimizations. And we did a whole bunch of other stuff too. We actually implemented an API on the backend and we also implemented a Twitter feed . And so we said , “when you go to subscribe, we’ll give you all these mechanisms” we gave you, you can subscribe by email, you can subscribe by text message. Here’s the API, so you can do whatever the hell you want with it. Here’s the Twitter feed. And then, I don’t know, there’s five different things you could do. So it was a little bit of scope creep, but it was awesome because we got to it and we said, well, we actually can do these things. We scrambled and made sure that all these things actually worked. And then, we did that and basically iterated by the next day, by Thursday, we had this thing that was pretty complete and pretty polished. And then by the time I showed the founders then, they’re like, “Holy crap, this is awesome. Like, this is pretty much everything we believe in.”
And the reason he said that was because we made a bunch of interesting other choices like, when you subscribed by email, you would get all the updates on a message. So you’d get an alert. And then you’d also get when the alert was updated and when it was closed, and everything else. But if you got a text message, we only alerted you when the thing started. Because if you were woken up in the middle of the night, it’s awesome that you now know Heroku’s down, but do you really need to know that, “Oh, we’re still working on it” every 10 minutes. Do you need to stay awake for that? We figured if you got the text message, if you really wanted to, you would then go to your computer and then follow along by email.
But part of the thing is that we’d have these huge debates about: do we need to let people choose? Because maybe I do want to know when it’s closed, I want to know all this stuff. Do we need to give you options and choices? And we said, “screw that no options and choices, let’s just think really hard, about what the right answer is, and we will give you that.” So you had an option, of course, of email or texts, but that’s it. And then when we made the rest of the choices for you. That’s one of the reasons that the founders really loved it. Because it was like we made it really, really simple.
So anyway, we iterated then by day four, Thursday, we had this, we actually launched it to our private beta list, with metrics because we said, “okay, what does success look like?” And that’s a thing I didn’t really mention, but in the very first iteration we even said, “what does success look like?” before we even started coding. And we came up with what our metrics were and we said, “well, if 10% of the beta list subscribes and keeps on there and doesn’t opt out after they get the first a few alerts, then that’s success.”
So anyway by Thursday afternoon, we had launched it and so we actually had numbers within four hours. We knew how many people subscribed and we got a bunch of feedback and everything else. So by Friday, by the time - the starter project was basically done at noon - we already had measured response rates. We knew that 20% of the people had actually signed up and stayed there; that this was actually valuable. We had the anecdata responses of people saying they loved it, but we had the numbers to back it up. And we were fully done. Now there were a few little bugs we fixed over the next week or two, but basically we shipped an entire feature, from start to end in a week.
The reason I really love this and the reason I think we should start caring about this is that this is really valuable for high-uncertainty projects. We didn’t know for sure what subscriptions should look like. We didn’t know what many of our features at Heroku should look like. And we really wanted to get feedback from the beta list early on too. And so part of that was a two way conversation with the beta folks. Whereas currently a lot of things we do is… We work on something for a month and then we ship it. And then actually in fact, we feature freeze in then wait several weeks before we get any feedback about it. But by then, we’re already working on the next iteration of it. And so we better be right in some level. I’ve always said this before though so speed does sort of solve all our problems. And the thing that GitLab really has going forward it is that we ship quickly. And so yeah, we ship it a month and even if we’re totally wrong, who cares, it’s just a month of effort we throw away. More realistically, most of the time we’re right and we just need to tweak it, in which case, then we’ll tweak it really quickly. It still does mean though that calendar time - it can take three months before we actually have a polished version of something. And, boy, I’d really love to get that cycle time down. Right. This is part of what we pitch. Right. We pitch our cycle time as meaning something. And it’s awesome what we ship in three months. And it’s awesome the sheer quantity of things we ship. So the bandwidth is high, but the latency, so to speak is, high as well, which is not a good thing. And product discovery can really get that latency down. It can mean that we ship things quicker and with higher uncertainty, we can discover - that’s the whole reason we call it Product Discovery - we can discover what the feature is supposed to be. The reason this all came up is because we were talking about: Do we design things ahead of time? Do we have things fully spec’d out before we hand it off to engineering? And that works for some types of problems and it’s really bad for some other types of problems. If you just sit there and design a static mock up and then say, “great, go and ship it.” But then it turns out to just not really satisfy anybody’s needs, then you haven’t really done anything. Or at least it’s two months before you realize how you’ve made a mistake and then you can go forward.
Bringing a little bit of Lean Startup thought on this, and I’ll try and wrap this up quickly, is: the difference for me between the way Product Discovery works and the way that Scrum works is Scrum can tolerate being wrong. The idea is you move quickly, and you can react to your customer telling you how you made mistakes, et cetera. Whereas lean assumes you are wrong, you just don’t know where you’re wrong. And so you want to get it out as quickly as possible so you can learn what you make your mistakes on. And that’s not a problem that you made mistakes; this is a high uncertainty situation. So get something out there in front of target users, beta users, whatever, as quickly as possible so that you can find out where you are wrong.
And I think that’s, in a lot of ways, different from our approach with GitLab too. We are tolerant of being wrong. We have this issue tracker. We have public contributions. We have all this kind of stuff, but still we’re basically marching forward assuming we are right. We’re doing an issue and we have the next issue and we have the next issue planned out. And we’re assuming that less and less, I mean, we used to assign five issues worth and we know that that’s not right, but still we’re basically like cross budget pipelines we’re doing right now. We’ve basically planned three releases worth. And we’re not listening to any feedback in the middle of that or any part of it really, we’re still just assuming we’re right and we’re delivering it. And we’re tolerant of making mistakes. And I think the big difference again, with Product Discovery is assuming we are wrong, we want to get there as quickly as possible. We want to learn. Also does tend to mean that we have a polished, a more polished product more quickly.
So anyway, that is, I think enough of my time.
Fabio: So, Mark, just the question for you, about your story, were you and your team just focusing on that specific feature during that week or so of work or are you also doing something else during that?
Mark: That is an excellent question. And that is probably the biggest downside of this process.
Actually, there’s two big downsides. One is that it is basically a hundred percent focused. Like the product manager, I would be doing other things, but the developers, the designers, they’re working a hundred percent on this one thing, which is great but means you’re doing no bug fixes, you’re doing no maintenance, you’re doing nothing else, whatever. So Marty Cagan who a lot of this stuff was inspired by… and by the way, so he’s got this really great book, but he’s got a better blog. Because his book is old and basically he doesn’t believe in everything he wrote in his book anymore, but he’s actually really a smart guy and his blog post is right on target. But if you read the book like I did and thinking, “well, this makes no sense. This is dumb.” It is dumb but his new stuff’s awesome. Anyway, he, in his book though proposed basically having two teams, like you’ve got your product discovery team, and that’s mostly about product and design and you’d have like one or two engineers allocated to doing the discovery. And then when that discovery is done, you’d pass it off to the delivery team. And so you’d have a discovery team and a delivery team. And then of course the delivery team can be working on anything else in the meantime. I personally, never did a discovery team and a delivery team separately, so I’m biased here. I’m not even sure I think that’s a good idea. His arguments were things like, well, if you do discovery, it’s still just a proof of concept. You’ll move faster if you’re not trying to write production code. But then pass it off to a delivery team that writes good production code. But from my perspective, I just had one team that wrote good enough code right away and we would ship it. And maybe we refactor it later on. But I don’t know, I didn’t do that. But the other aspect is that potentially if you have that delivery team, then that delivery team can be working on bugs. Instead, what we would do is every once in a while, we would not do a discovery sprint and we would do a bunch of bug fixing sprints or whatever, or what you’d do is you’d wrap up a bunch of bug fixing into some other topic that then you would do a discovery sprint on or something.
But also I’ll just say in practice, we just shipped a lot in this team and it wasn’t, in practice, a problem, but I know that we do things differently here, and we might very well need more maintenance and whatever.
The other big downside to this is the synchronous communication. We had at least four hours of overlap with every member of the team. In fact, in the early days it was seven or eight hours. Everybody was in the same building. We would discuss something in the morning at our stand up, we would sync back up four hours later, and then we sync up again four hours later.
And there was a lot of communication. As a product manager, it took at least half of my time just working with the discovery stuff. So massive high bandwidth requirements from the product. The positive side of course, is that, and this is where a lot of this stuff was inspired by, was that, engineering would be like, “Oh, I tried to implement this thing. And it’s a problem. What do we want to do?” Or “this spec was unclear.” And so instead of just getting stuck, putting in a comment on an issue and then going off and doing something else, you would say, “okay, get the product manager and the designer together right then.” And we would make a decision within five minutes.
That was actually before we had the product discovery sprint. That was the precursor to all this. If you’ve got a problem, basically pull the red line on the Japanese Kanban kind of thing. Production stops, you solve the problem, then move on. And that actually was incredibly powerful, frankly.
It meant that our calendar time gets really reduced. I really don’t know how the hell that’s going to work in an asynchronous globally distributed world, which is the big reason that I haven’t been pushing this more. I think it can, and it might mean that you do something like: you’ve got your delivery team that does the normal stuff asynchronously, and then you’ve got a different team that at least has four hours of overlap. It might mean that you can’t have globally distributed, but you can have continentally distributed. I don’t know, throwing this out there.
I’ve interviewed many people for GitLab, and one question I often get is about what it’s like being remote. GitLab is famous for being all remote, and possibly the largest all-remote company. But when I’m asked that question, I like to go in a different direction. GitLab isn’t just about being all-remote, or remote-first, it’s about being people-first. We’re not all remote because of the cost of office space or the ability to hire the best talent all over the world, or any of the other great things about going remote. These are benefits, but they’re not the reasons. We’re all remote because we’re people first, and people live all over the world outside of major cities. Why should we make them move? Why ask people to spend hours commuting? But when you put people first, it’s more than just being remote.
I used to work at a place that was remote-friendly, eventually with 50% of the workforce being remote. It started out that we allowed people to work remotely, but only if they agreed to work on an SF schedule. We eventually relaxed that (as it’s a pretty ridiculous requirement), but only allowed individual engineers to work remotely. Eventually we let managers be remote, but still I’d hear people comment about how leaders can’t be remote. We had one person who lived in Seattle fly in every Monday and out every Thursday to accommodate our HQ-centric perspective. Eventually that faded, and we started hiring more leaders remotely. When one particular leader was hired, who had tons of experience working remotely, he presented a few tips for people to successfully work remotely. They included things like having a set schedule for yourself and making sure your team knew your schedule, and to let them know if you were going to deviate from it. Makes sense, right? If you have to be away, it’s harder for people to notice when you’re remote, so be proactive in your communication. When you start work in the morning, say hello in your team channel, if you step away, let people know, when you’re done for the day, say goodbye.
But GitLab takes a different approach. We explicitly say not to check in and check out of your team channel. We used to ask you to mention what you were working on every day, which had innocent intentions, but cut that part out of our handbook because it felt too big-brother-esque or butts-in-seats minded. Your schedule is nobody else’s business. Your results are what matters. If you need to go to an appointment in the middle of the day, go. If you’ve got to pick up the kids from school, go. Heck, if you just need to take a nap, go for it. We have people all over the world, there should be no expectation of an immediate response anyway, so write your communication clearly and concisely and prepare for an asynchronous response.
For me, I love that when my kids come home from school (back when they actually went to school), and they’re excited to talk to me about something, they can interrupt me. It only takes 15 minutes, and then I’m back to work, but those 15 minutes mean the world to them, and to me. If I waited 2 hours until my workday was done, the excitement would be gone. It would be even worse if I had to wait an extra hour to commute home. When my kids were little, there was a period of time when I’d make it home from work just in time to put them to bed. I’d miss dinner, I’d miss bath time; I’d get maybe 15 minutes total with them during weekdays. Now I have breakfast and dinner with my family every day. I even occasionally have a lunch date with my wife! That wouldn’t be possible without being remote, but it also requires putting people (and their families) first.
Being all remote is just one consequence of a deeper commitment to putting people first. As another example, GitLab, like many companies had an all-company call. But unlike many companies, the main focus wasn’t on one-way presentations of company or department announcements to the rest of the company, the focus was on two-way communication about people, as individuals. This wasn’t a daily standup where people talk about that they did yesterday, what they’re doing today, and what blockers they have; it was a chance for people to talk about their personal life. A favorite topic was what you did the previous weekend, or what your plans were for the following weekend. As we grew, we couldn’t let people talk every single day, but we’d assign people to talk on certain days of the week, and eventually to a 2-week cycle. I’m an introvert and don’t generally like engaging in small talk, but I found myself really looking forward to these calls. In the in-between times, I’d take notes and prepare what I wanted to share with the team. And people didn’t just share warm-and-fluffy topics, some of the topics were deeply personal. People really opened up.
We also have an all-company summit (now called Contribute) every 9 to 12 months. Again, the focus wasn’t on getting work done, because we better be able to get work done remotely, but in connecting to each other in ways that take advantage of meeting in-person. We’d go ziplining in Mexico, or tour Santorini in Greece, or hike Table Mountain in South Africa. During one particular summit, I arrived and met up with the other GitLabbers, and gave one of them a hug. Then it really hit me how well we’re able to connect as people. Not only was this the first time I had met this person “in person”, but this was the first time we had even ever had a direct conversation. Our only interactions were during the company call, and yet we each felt like we knew each other really well because of how much we’d shared. And when GitLab grew too large to continue having both the department announcements and the personal calls? I feel like every other company I’ve been at would make the obvious choice, to drop the personal content and stick to the essential content. But that’s not what GitLab did. We cut the departmental content and kept the company calls about personal connection.
These are the main examples I bring up, but the reality is that there are a ton of decisions made every day where things could go one way or the other. And most companies sooner or later end up deciding to protect the bottom line, or whatever story they tell themselves to justify doing something that isn’t great for the employees. But GitLab has always chosen to make the hard, but right call to continue to put people first, and that makes all the difference.
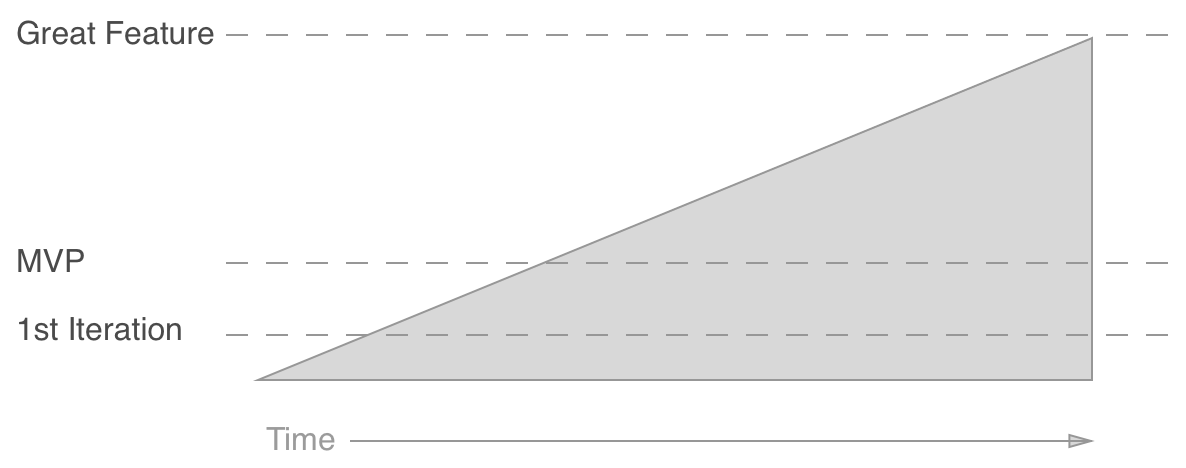
Everyone knows to ship small and iterate. Hopefully you’re getting to an MVP as quickly as possible so you can learn as quickly as possible. And hopefully you’re not stopping there; going beyond an MVP to ultimately develop a great feature.
But do you keep going on a single feature until it’s awesome before moving on to another feature? If so, you’re doing depth over breadth. This is great, and nothing to be ashamed of. But there are other options. You can also do breadth over depth and ship a bunch of MVPs, never really improving any single feature until you’re “done”. Maybe then you go back and improve a bunch of the features, and slowly raise the quality of the entire produce until it’s great. Again, this is a valid approach.
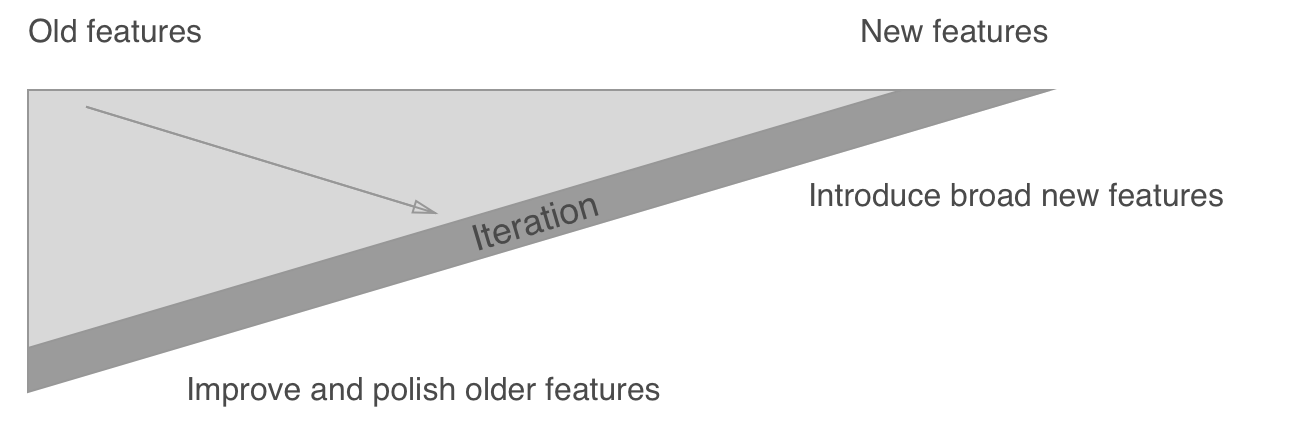
But let me introduce another approach. The depth triangle.
Here, you constantly develop new features and get them to the coveted MVP state, then pick up a new feature, ship an MVP. But after a while, go back and improve one of your older features. There can be several months lag before you truly polish a feature, but you do eventually get there, all while continually increasing breadth.
Product Discovery is a term for working very quickly to discover a product or feature as you work on it, with feedback from users, in an area of significant uncertainty. The process described here works best when innovating in a somewhat well-known space. e.g. adding a new feature into an existing product.
When doing product discovery, don’t start with a plan for the entire sprint. Plan enough for the first iteration with a goal of finishing within 1-2 days. Then ask “what’s the next most important thing”, and work on that for an iteration. Ideally, do 5 iterations a week, with each one needing a little planning.
Start with some brainstorming on what could be done without regard to time (call this “Think Big”), then narrow down to what the most important thing is to deliver in 24-48 hours (call this “Think Small”). Then work on that, as a team, and deliver the first version within 1-2 days. Then see how it feels, and decide what the next most important thing to work on is, and iterate. Then iterate again. And again. At some point, have external users take a look for validation, and add some metrics for tracking success. By the time you’re done, you’ve got a beautiful, polished, and valuable project finished and validated.
The thinking big part is great to get people out of local optima and think about the big picture. Context swap everything you can on the subject in a short period of time. Go crazy with ideas. Then narrow that down to the core of the feature. What’s the one thing you can deliver that would satisfy the goal without all the fluff. Sometimes it’s surprising what turns out to be the main point and what we can get away without.
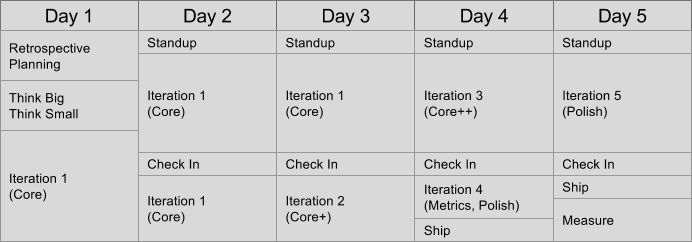
Example Week
Details
Process
1 week sprints. Planning is 2 hours. Standups are daily and walk-the-board style rather than yesterday/today/blockers style.
Pre-Plan
PM and Eng Management get together at the end of the previous sprint to gain a better understanding of priorities so we can go into the sprint better prepared for planning with the team.
Retrospective
Retrospective is about meta — it’s not a status update on the last day or even the last week of work. It’s about what went well, what didn’t, and most importantly what would we do differently or what can we learn from it. Sometimes we can’t do anything more than surface a problem with no immediate solution. Retrospective should aim to be only 15-20 minutes with a hard-stop at 25 minutes. If something really deserves more time, perhaps it should be a separate meeting (with less/more/different people).
Prioritize and allocate
Decide on project/product/feature to work on (and who will work on it, if there’s more than one project ongoing, which shouldn’t happen very often).
Think big and think small
Expand feature - what can it be.
Shrink feature to something achievable in 24-48 hours - cut scope to the minimum to make it functional and shippable.
Define metrics to watch and define what success looks like.
I’ve heard that Google and maybe Apple do some kind of expand and contract phases, although I think one of them expands on a Friday and then contracts on a Monday. Anyway, it’s a powerful tool.
Development
Deliver iteration of the product/feature.
Test with ourselves, coworkers, and users.
Decide on and implement the most important improvements, whether they are functional, UI, or UX.
Repeat.
The first iteration should take 24-48 hours, with the rest taking 4-8 hours, for a total of 5 iterations in a week. 7 iterations if you’re awesome.
Delivery
Deploy
Measure success of product/feature with real customers (private beta, public beta, or GA)
Sometimes you can expand from internal alpha to private beta to public beta within a single sprint. Sometimes you can only get to one stage within a week and you increase scope in subsequent sprints. The important thing is to always aim for learning as quickly as possible. If internal users are still providing surprising feedback, and you’re learning from it, then that’s still valuable.
Sprint Philosophy
Premature optimization is the root of all evil
Seriously, read Lean Startup. Putting any time in something that is later going to be thrown away because it turned out to be the wrong thing is the worst efficiency possible. Do just enough to validate. Focus on your biggest risks first.
How does this benefit the developer (user/customer)?
This doesn’t mean the customer is always right, or that we’re not allowed to think for ourselves, but that we should always make sure the user is represented in the discussion. Don’t talk (only) about internal or engineering benefits. Make sure it’s going to be of benefit to the end-developer.
Always work on what’s most important right now
Sometimes breadth-first beats depth-first. If customers are having a horrible experience with documentation, how can we say another iteration of notifications is more important?
But timing matters too — if we just finished an iteration on something, there’s value in leveraging that momentum (reducing context switch, etc.).
But don’t forget that we learn more about a feature as it’s being used, so letting something be out in customers’ hands for a while might result in better insights into the next most important thing rather than just theories in our heads.
Work on one project at a time
It’s important for the whole team to work on the same project. It doesn’t have to be the same feature, but it should be the same space. It sucks if one developer is working on something completely unrelated, or design is working on the next project ahead of engineering.
Work on one project a week
It’s important to plan a single project for an entire (week) sprint. Finishing one project on Wednesday then starting a new one on Thursday rarely works, at least for product discovery work.
Always finish sprints cleanly.
Don’t let WIP spill over the weekend. Saying “I’ll finish it on Saturday” rarely works, and even if it does, it can’t be peer reviewed and shipped until Monday and then it’s impacting the next sprint. This isn’t about working overtime. It’s more important to ask what scope can be cut so you still deliver on time. If you really want to code on your weekends, pick up something new for fun.
Collaborate and communicate
Communicate throughout the day, not just at standup.
Eliminate blockers — Tight loop always wins. When a decision needs to be made, get the relevant people together and make the decision - 5 minutes or less.
Roles (PM, Designer, Engineer) should only be used to resolve tie-breakers. Everyone’s opinions should be valued regardless of origin. The entire team owns the solution. Nothing is more powerful than ownership.
Iterations FTW, Refactors FTW
Everything is an experiment. Start with a hypothesis.
Iteration is better than perfection - But actually iterate; iterating once is called doing a half-assed job. It’s OK to ship things that aren’t perfect.
It doesn’t count until it ships. (Ship in this case can mean the point where you can learn something.)
Don’t be afraid to take time to refactor.
Design is about understanding and solving problems, not just the looks
Designers work in code whenever possible, using Sketch/Photoshop when necessary.
The most important thing for a product manager, is to be right. If you’re not right over 80% of the time, you’re just not cutting it. If you use all the right tools, but are still wrong, it doesn’t matter. And if you’re right and don’t use any tools, it doesn’t matter. But of course, using the right tools can help you be right more often, so let’s take a look at some of the tools that help you do that.
Getting Started
There’s always the classic SWOT analysis (Strengths, Weaknesses, Opportunities, Threats). It’s a simple tool that helps you get the lay of the land, so to speak. In a startup, you likely already know the answers, but sometimes writing things down helps crystalize things, or at least communicate things to other people that haven’t thought about it as much. I don’t use it much personally, but if you’re new to this, it’s a great place to start.
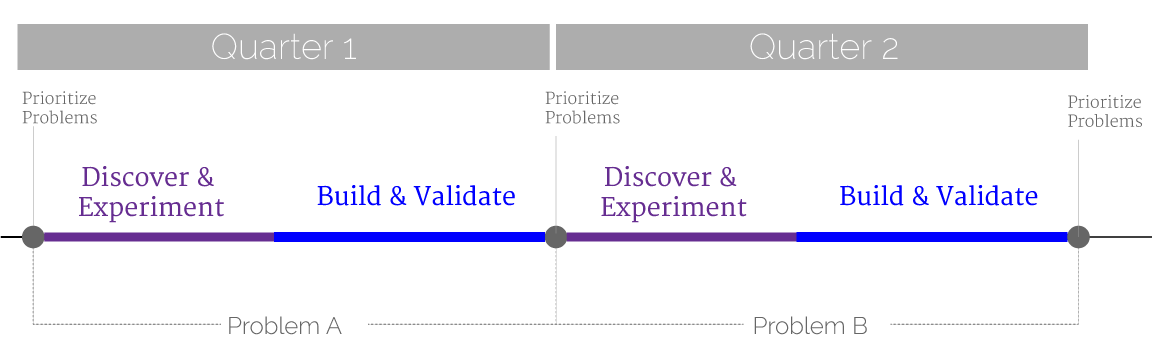
In an early stage startup, you’ve got to have a great vision for where you’re going (and a mission and shared values), but that doesn’t mean having a rigid 3 year roadmap. Your world changes too quickly and you’re learning new things about your business every day. But that also doesn’t mean you don’t need planning at all. You have to make sure you’re doing the most valuable work at any given time. Just focus on one quarter at a time. Specifically, answer the question, what would be stupid for us not to do in the next 90 days? Make sure to include your customers’ perspective in the planning, but don’t forget to ask engineering as well. They’re close to the problem and have great ideas that customers may never ask for, yet truly need.
Put all the ideas up on a board, with a small description for each. Pandora used a single presentation slide for each idea. Marty Cagan pitches a Product Opportunity Assessment with 10 key questions. Lately I just use a Trello card with 4 simple questions (and links to any relevant links to prior art, proof of concepts, or supporting documents):
What’s the problem being solved?
Why is now the time to solve it?
Roughly how much effort is involved and from which teams?
How is this going to help us achieved our business objectives?
Then filter the ideas down to the most important big ideas. Get the exec team together and vote on them. Remember, focus means saying “no” to a thousand good ideas.
Ship Small and Iterate
When working on a project, don’t get caught up in defining everything up front, even if you’re only looking at 3 months or less. The sooner you get things out of your head and into customers hands, the faster you’ll learn. I’m a big fan of product discovery popularized by The Lean Startup movement. Ship small and iterate.
Aligned Empowerment
Your team will grow too large to do the above planning all together. And really, at some point your company will be capable of delivering more than one person can organize. You’ll need to hire more product managers, and divide up the product space. Resist the temptation to keep central control over everything. Empowering small teams, each with a product manager, to make decisions about what they work on is incredibly powerful. The people closest to the work should be trusted to know what to tackle next. And teams work best when they’ve been working together for a while so durable feature teams are your friend. But don’t let it devolve into anarchy. Your teams need to be aligned to common goals. A compelling and well-articulated vision is key here.
Roadmap
Eventually, as your startup grows, you’re going to need a roadmap. Especially for enterprise customers, they’re not just buying your product, they’re buying the future version of you. But rather than submit to their demands, create an agile roadmap that understands that you can only see clearly for so far and your vision gets blurry past 6 months.
Start with your product vision, brainstorm ideas, separate the big “boulders” from the “pebbles”, then categories the boulders by level of commitment. Don’t be too concerned about making sure everything is committed with a timeline. Some projects can be worth committing to even if you don’t have a clear idea how long they’ll take to finish. Then of course there’s those projects you can’t completely commit to, but will likely deliver at some point. And then there’s the big visionary stuff; the ideas that might not show up in a year, or even five years, but these aspirational goals help define you. Lastly, it’s just as important to write down what you won’t do. Once you’ve got all that, you can cluster things down into a sharable roadmap.
Also consider the “problem roadmap“ rather than the “product roadmap”.
Lean canvas
Yeah, you can try out the Lean Canvas, especially if you’re still pre-funding. I haven’t used it myself, and I find the format rather dry, but it seems to be gathering momentum.
Closing
Well, that’s all I’ve got time to cover today, and I feel like I’ve left out a lot of great pieces like balancing customer requests, metric-moving improvements, and visionary features. And the Think Big, Think Small exercise. Maybe I’ll cover those another day.